Por favor, ingresa tus credenciales para acceder a tu cuenta.
Introduce tu código de autenticación
Revisa tu aplicación de autenticación para ver el código.
Introduce el código de verificación
Revisa tu correo electrónico para ver el código que te hemos enviado.

Cada vez que entramos en un sitio web y vemos el texto que hay escrito, está codificado en UTF 8 y por ese motivo somos capaces de leerlo correctamente o mejor dicho, nuestro navegador es capaz de "entenderlo" y mostrarnos la información.
Esto también pasa cuando recibimos un correo electrónico o se envía cualquier tipo de información entre dispositivos de manera digital, pero veamos qué es y cómo funciona exactamente UTF 8.
Qué es el sistema de codificación UTF 8 y para qué sirve
TABLA DE CONTENIDOS
Qué es UTF 8
UTF 8 son las siglas en inglés de "8-bit Unicode Transformation Format" y se trata de un sistema de codificación de caracteres Unicode. UTF 8 es un estándar en la web, ya que la mayor parte de ellas lo utilizan y es compatible con todos los programas de correo electrónico que existen o al menos los más utilizados.
Cada sitio web que visitas especifica qué tipo de codificación está usando o al menos debería indicarlo si se trata de un sitio medio serio y la codificación más utilizada es, sin duda UTF 8.
Si quieres comprobar si una web está utilizando este sistema de codificación, sólo debes de buscar en su código, la etiqueta:
<meta charset="UTF-8">
Y lo mismo si tienes una web y quieres utilizar este sistema de codificación, deberías añadirla después de la etiqueta head.
Por si te lo estás preguntando, si estás usando un CMS tipo WordPress o Joomla, estarás utilizando UTF 8, así que no deberías modificar nada al respecto, a no ser que tengas algún problema con los caracteres de la web.
Qué importancia tiene UTF 8 en la web
No todo el mundo escribe y habla de la misma forma. Con la llegada de la época digital, cada idioma creó sus propios estándares de codificación de caracteres, lo cual podía funcionar, siempre y cuando no trataras de comunicarte de manera internacional.
Es fácil imaginarse el problema, por ejemplo, el italiano y el español son muy parecidos, cierto, pero en español tenemos una eñe (ñ) que no existe en el idioma italiano. O algo más cercano con la ce cedilla (ç) que se usa mucho en catalán, pero no existe en español.
Si cada idioma usara sus propios sistemas de codificación, cada carácter que no estuviera en nuestro idioma sería ilegible o peor aún, tendrían asignada la misma codificación con distintos caracteres, por lo que podría llegar el caso de que en el texto original se escribiera un "Sí" y otro sistema de codificación lo mostrara como un "No."
Ahora escala esto a todos los idiomas del mundo y piensa en los países asiáticos o en el diccionario cirílico... las comunicaciones digitales internacionales eran muy complicadas y se tenían que estandarizar.
Para esto se creó la codificación UTF 8, que es capaz de interpretar todos los caracteres que existen en el estándar Unicode y por lo tanto, todos los caracteres que existen en el mundo. Si todos usamos la misma codificación de caracteres, no tendremos problemas en ver, realmente, los caracteres que se hayan utilizado, otra cosa es que sepamos qué quieren decir, pero para eso tenemos que conocer el idioma en el que están escritos.
Esto debes tenerlo claro, UTF 8 no traduce el idioma en el tuyo, pero si usas la eñe (ñ) en tu web, cualquier usuario que acceda al sitio verá sin problema el carácter bien escrito, aunque no sepa qué quiere decir.

El estándar Unicode
UTF 8 es un sistema de codificación, pero el estándar que codifica e identifica todos los caracteres de todos los idiomas que existen en el mundo se llama Unicode.
Los ordenadores o sistema informáticos no son como la mayoría de la gente piensa, cuando escribes cualquier letra en un texto, no la identifican como tal, sino por un código. Este código que el ordenador interpreta, lo toma del estándar Unicode y por eso cuando escribimos la letra "A" nuestro dispositivo es capaz de representarla.
"A" mayúscula:
Número en Unicode: U+0041
Código HTML: A
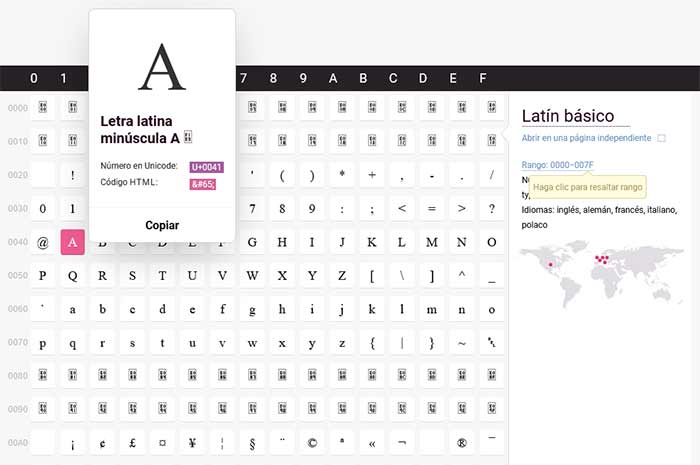
Esto es así en cualquier dispositivo que utilice Unicode como estándar, esté en la parte del mundo que esté o tenga configurado su dispositivo en cualquier idioma. Es decir, que el código Unicode U+0041 es el de la letra "A" y ningún otro carácter en el mundo podrá usar ese mismo código, sea del idioma que sea.
¿Quieres hacer una prueba? Si estás delante de tu ordenador, abre cualquier documento de texto, como por ejemplo el Bloc de Notas de Windows y haz lo siguiente:
- Mantén pulsada la tecla Alt, que suele estar la izquierda de la barra espaciadora.
- Pulsa el número 6 y suéltalo.
- Pulsa el número 3 y suéltalo.
- Deja de pulsar la tecla Alt.
Sí, el resultado será una letra A, como si la hubieses escrito directamente, pero has utilizado el código Alt, que también estandariza Unicode.
Si quieres conocer todos los códigos Unicode de todos los caracteres, puedes visitar la siguiente URL: Unicode-table.com. Como podrás comprobar, no sólo encontrarás caracteres, también símbolos y hasta emojis con su identificador Unicode.
UTF 8 + Unicode
Hemos visto que el estándar lo proporciona Unicode, pero es sólo eso, un estándar, no una forma de que un ordenador interprete el código Unicode. Para esto se necesita un codificador que se encargue de traducir el identificador Unicode, en algo que un sistema operativo entienda y aquí es donde entra en juego el sistema de codificación UTF 8.
UTF 8 es capaz de interpretar todos los caracteres Unicode que estén identificados en su base de datos y le dice al sistema qué tipo de carácter tiene que utilizar ya que lo traduce a binario, que es "idioma" que entienden los ordenadores.
Si todos los sistemas usan UTF 8, no tendrán problemas en interpretar y mostrar la información de manera correcta, sin importar el idioma en el que estén escritos.
UTF 16 y UTF 32
No sólo existe UTF 8, también podrás encontrar UTF 16 y UTF 32 como sistemas de codificación. Las 3 opciones usan como estándar Unicode, por eso no hay problemas, pero sí que existen diferencias en cómo lo hacen.
Esto es algo más técnico, pero digamos que UTF 8 es más eficiente a la hora de codificar la información obtenida. Una de sus ventajas respecto a la de sus hermanos, es que interpreta el sistema ASCII, el sistema de codificación estándar inglés anterior a Unicode, con sólo un byte cada uno de ellos y es directamente compatible.
En UTF 16 y UTF 32 no es así y se utilizan más bytes, sobre todo UTF 32, que utiliza siempre 4 bytes de forma fija para cualquier carácter, lo que le hace consumir más memoria, aunque siempre utiliza un ancho fijo para cada carácter, lo que puede ser una ventaja en algunas circunstancias.
En UTF 16 funciona bien si no se utiliza ASCII como de manera principal o no se tengan en cuenta todos los caracteres que existen en Unicode. Por lo general, utilizar UTF 8 es una opción más práctica, aunque en algunos casos suelen haber excepciones.
Conclusión
Quizás ya habías visto UTF 8 en algún sitio, sobre todo si gestionas una web, pero es probable que no supieras lo importante que es utilizar UTF 8 como codificador. El estándar Unicode es también muy importante en todo esto, ya que, si no existiera, UTF 8 no tendría dónde comprobar qué está mostrando la información correcta a todos los usuarios.
Hoy por hoy, utilizar UTF 8 es la mejor marea de evitar los problemas de codificación en sitios web o correos electrónicos. Según el sitio w3techs.com, que se encarga de realizar comparativas de uso en diferentes áreas tecnológicas, UTF 8 es usado en el 97.9% de todos los sitios web hoy en día, así que parece una apuesta segura.


Hosting
VPS
Servidor VPS administrado alojado en España. Incluye migración gratis y soporte técnico 24x7.
Dominios
Más de 550 extensiones de dominio para elegir. Compra tu dominio en pocos pasos de forma cómoda.
Servidor Cloud
Continúa con tu compra
¿Es la primera vez que compras?
Si ya eres cliente de Axarnet