Por favor, ingresa tus credenciales para acceder a tu cuenta.
Introduce tu código de autenticación
Revisa tu aplicación de autenticación para ver el código.
Introduce el código de verificación
Revisa tu correo electrónico para ver el código que te hemos enviado.

El archivo robots permite a los buscadores, como Google, que puedan rastrear tu web para indexar su contenido y poder mostrarlo en los resultados de sus búsquedas. Debido a lo importante que es para Google para llevar los usuarios nuestra web, el archivo robots.txt es muy importante y una configuración errónea, puede hacer que nuestra web desaparezca de los buscadores, así que hay que configurarlo correctamente para evitar problemas.
Qué es el archivo robots y por qué es importante
TABLA DE CONTENIDOS
- Qué es el archivo robots.txt
- Por qué es importante el archivo robots
- Cómo se crea un archivo robots.txt
- Cómo configurar un archivo robots.txt
- Dónde se sube el archivo robots.txt
Qué es el archivo robots.txt
El archivo robots, pese a su futurista nombre, no es más que un archivo de texto, con la extensión .txt. Al tratarse de un archivo de texto, puedes crearlo desde cualquier ordenador, aunque eso sí, el nombre deberá ser siempre el mismo: robots.txt.
Dentro del archivo robots.txt podemos añadir una serie de directrices para indicarle a los buscadores qué pueden indexar y qué no. Hablamos de buscadores, pero en realidad nos referimos a cualquier tipo de bot, de ahí su nombre, que se dedique a escanear la red en busca de contenido.
Por qué es importante el archivo robots
Bueno, ya hemos dicho que con la configuración del archivo robots, podemos permitir o no, el rastreo de nuestro sitio web por parte de los buscadores. Si desde el archivo robots.txt no permitimos este rastreo, nuestra web no aparecerá en Google, ni en el resto de buscadores.
Esto, si tu intención es que la gente llegue a tu web, que es lo más normal, es muy importante y tener el archivo robots.txt bien configurado es beneficioso para el SEO de tu web.
Es posible que estés pensando que es mejor que el archivo robots deje el camino abierto a todos los bots que pasen por tu web, así, podrán indexar y mostrar todo el contenido que tengas publicado en el sitio. Pero Google o cualquier otro rastreador, no sabe cuál es el contenido relevante de tu web y cuál no lo es.
En una web pueden existir multitud de URL's que no nos interesa para nada que estas sean indexadas por los buscadores, ya que no aportan nada a nuestra web. Por ejemplo, las páginas de login o las miniaturas de las imágenes, no tiene mucho sentido que sean indexadas.
Desde el archivo robots.txt podemos indicar a los buscadores la prioridad del contenido que queremos que sea rastreado, obviamente, con el contenido más relevante del sitio. Todo esto beneficia el SEO de nuestra web, lo que se traduce en un tráfico más rentable y un mejor posicionamiento web.
Cómo se crea un archivo robots.txt
Para crear un archivo robots.txt sólo necesitas un editor de texto, aunque algo importante, un editor de texto plano, es decir, que no tenga formato. Si usas un editor tipo Microsoft Word, le dará un formato y no podrá utilizarlo, así que usa, por ejemplo, el Bloc de Notas en Windows o cualquier otro editor de texto plano.
Es importante que guardes el nombre del archivo como: robots.txt, sin mayúsculas o ningún otro carácter, ya que, de lo contrario, no funcionará.


Una vez lo hayas guardado, ya tienes un archivo robots creado, aunque ahora tienes que configurarlo, ya que no le hemos añadido ninguna información.
Cómo configurar un archivo robots.txt
La parte más complicada viene ahora, ya que hay que configurar el archivo robots.txt con los parámetros que queramos, aunque como la estructura es siempre la misma, facilita mucho las cosas. La estructura es siempre la misma y hay que indicarle dos cosas:
- El nombre del rastreador o bot
- Lo que queremos que haga
En el archivo robots.txt, al nombre del rastreador se le llama User-agent y la acción que queramos que haga, que se llama directiva, se añadiría en la línea siguiente del archivo. Por ejemplo, si quieres que el bot de Google pueda rastrear todo tu sitio podrías lo siguiente:
User-agent: Googlebot
Allow: /La barra inclinada (/) es la raíz del sitio y se indica para el directorio principal. Ahora vamos a hacer lo mismo para el rastreador de Bing, así que podríamos lo mismo, pero con el bot de Bing, lo que nos dejaría lo siguiente:
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
Como existen muchos bots y no queremos perder el tiempo averiguando su nombre y añadiendo líneas continuamente en el archivo, podemos usar un comodín en el User-agent, para indicarle a cualquier bot que llegue a nuestro archivo robots, lo que tiene que hacer:
User-agent: *
Allow: /
En realidad, la directiva allow para permitir el acceso a todo el sitio no se utiliza, ya que los rastreadores van a rastrar tu sitio tarde o temprano, pero así lo puedes comprender algo mejor. Ahora vamos a indicar que NO queremos que se rastree ninguna URL de nuestra web por parte de ningún bot. Tómalo a modo de ejemplo y úsalo con precaución, porque Google no indexará tu sitio si añades lo indica en el archivo robots.txt:
User-agent: *
Disallow: /
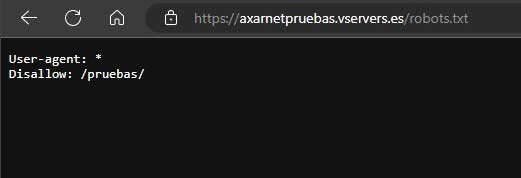
Como verás la sintaxis es siempre la misma y usando las directivas puedes indicarle a los rastreadores qué quieres indexar y qué no. Por ejemplo, si quieres que se rastree todo el sitio menos una carpeta en particular, llamada pruebas, el archivo robots.txt sería así:
User-agent: *
Disallow: /pruebas/

Así que usando las directivas Allow y Disallow, puedes crear el archivo robots.txt acorde a tus necesidades.
Ejemplo archivo robots.txt de WordPress
Por ejemplo, un robots.txt de una instalación de WordPress por defecto sería así:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Como verás, en el nombre del rastreador, recuerda que en el archivo robots se le llama User-agent, no se pone ninguno y se añade un asterisco (*), que se trata de un comodín para indicar las directivas que indiquemos se aplican a todos los rastreadores.
En la siguiente línea vemos que pone Disallow (Rechazar), el directorio /wp-admin/. Lo cual tiene mucho sentido, ya que se trata de un directorio administrativo de WordPress y no contiene contenido relevante para el usuario.
Y en la tercera línea vemos que pone Allow (Permitir) un archivo que se encuentra dentro del directorio wp-admin, llamado admin-ajax.php. ¿Cómo es posible? si le hemos dicho que no queremos que se rastree el contenido de ese directorio, pero si que se permite el rastreo a un archivo en particular que está dentro de ese mismo directorio.
Así es, se pueden añadir excepciones gracias al archivo robots.txt, para que se rastree sólo un archivo que está dentro de una carpeta a la que no le permitimos el rastreo.
Dónde se sube el archivo robots.txt
Ahora que ya tienes creado tu archivo robots, debes de subirlo a la web para que funcione. Para hacer esto, puedes utilizar el Administrador de Archivos de tu panel de control o si lo prefieres, utilizar un programa FTP con los datos de acceso, pero necesitas tener acceso al hosting.
En Axarnet, te proporcionamos el acceso al panel de control Plesk al contratar cualquiera de los planes de hosting que ofrecemos, así que lo tienes muy fácil para subir tu archivo robots.txt. Sólo tienes que acceder a tu área de clientes y seleccionar la suscripción en la que quieras subir el archivo.
Después de acceder al administrador de archivos, tienes que localizar el directorio httpdocs. El directorio httpdocs es la raíz del dominio por defecto, así que es ahí donde debes subir el archivo, pero si tienes la web en otro directorio o en un subdominio, deberás subirlo en el directorio que corresponda. Por lo general, si sólo tienes un dominio en el hosting será httpdocs.
Par subir el archivo robots.txt que tengas en tu ordenador, accede a la carpeta desde el Administrador de Archivos y pulsa el botón más (+) que verás en la parte superior y desde ahí Cargar Archivo.

Ahora sólo te quedará buscarlo en tu ordenador y esperar a que termine de subirse al hosting, que será casi instantáneo. Si quieres comprobar si el archivo robots.txt está bien subido, sólo tienes que poner la URL en cualquier navegador web y ver si se muestra correctamente.
Conclusión
Ya has visto qué es un archivo robots y lo importante que es para que tu web sea indexada por los buscadores. Ten en cuenta que, si estás usando un CMS tipo WordPress o Joomla, ya tendrán creado su archivo robots.txt por defecto, el cual puedes comprobar poniendo la URL en el navegador, pero puedes modificarlo o crear uno como consideres oportuno.
Sobre si los bots hacen caso de las directivas que añadimos en el archivo robots, depende del bot. Los rastreadores de Google y Bing, por ejemplo, seguirán las indicaciones Allow y Disallow, pero otros bots no lo tendrán en cuenta y rastrearán todo el sitio si así lo consideran. Las directivas del archivo robots.txt son indicaciones a los bots, pero no son un impedimento, así que tenlo en cuenta.

Hosting
VPS
Servidor VPS administrado alojado en España. Incluye migración gratis y soporte técnico 24x7.
Dominios
Más de 550 extensiones de dominio para elegir. Compra tu dominio en pocos pasos de forma cómoda.
Servidor Cloud
Continúa con tu compra
¿Es la primera vez que compras?
Si ya eres cliente de Axarnet